

* 입출력에 버퍼 적용하기

ⓛ 버퍼 적용 전
파일을 읽을 때 바이트 개수만큼 읽으며 읽은 바이트 외에 나머지는 의미가 없다 !
디스크가 나눠진 섹터(512 byte)를 다루는데 한 파일이 저장된 주소는
공간이 남아있더라도 다른 파일이 주소를 가질 순 없다 !
(* 크기와 디스크 할당이 다른 이유 - 섹터 단위로 주소를 저장하기 때문)

② 버퍼 적용 후
seek time 이 오래 걸리게 하는 요인이기때문에, seek time을 줄이기 위해서
읽는 byte를 증가시킨다.
byte[] buf = new byte[8192];
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class MyFileInputStream extends FileInputStream {
byte[] buf = new byte[8192]; // 8KB
int length; // 버퍼에 저장한 바이트 수
int pos; // 읽을 바이트의 인덱스
public MyFileInputStream(String name) throws FileNotFoundException {
super(name);
} @Override
public int read() throws IOException {
if (pos == length) { // 버퍼 데이터를 다 읽었다면,
length = this.read(buf); // 버퍼 크기만큼 파일에서 데이터를 읽어들인다.
pos = 0; // 버퍼 시작부터 읽을 수 있도록 위치를 0으로 설정한다.
}
return buf[pos++];
}
}* 바이트 배열에서 데이터를 읽을 때 주의할 점 !

데이터를 찾는 속도를 높이는 것이 데이터를 읽는 속도를 높이는 방법이다 !
package com.eomcs.io.ex06;
import java.io.FileInputStream;
import java.io.IOException;
public class BufferedFileInputStream extends FileInputStream {
byte[] buf = new byte[8192];
int size; // 배열에 저장되어 있는 바이트의 수
int cursor; // 바이트 읽은 배열의 위치
public BufferedFileInputStream(String filename) throws Exception {
super(filename);
}
// 파일에서 버퍼로 왕창 읽어 온 횟수
int readCount = 0;
// 버퍼를 사용하는 서브 클래스의 특징에 맞춰서
// 상속 받은 메서드를 재정의 한다.
@Override
public int read() throws IOException {
if (size == -1 || cursor == size) { // 바이트 배열에 저장되어 있는 데이터를 모두 읽었다면,
if ((size = super.read(buf)) == -1) { // 다시 파일에서 바이트 배열로 데이터를 왕창 읽어 온다.
size = 0; //
return -1;
}
readCount++;
System.out.printf("==>버퍼로 왕창 읽었음! - %d 번째\n", readCount);
cursor = 0;
}
return buf[cursor++] & 0x000000ff;
// 위의 리턴 문장은 컴파일 할 때 아래의 문장으로 바뀐다.
// int temp;
// temp = buf[cursor];
// cursor++;
// return temp & 0x000000ff;
}
}
* 29. 입출력 성능을 높이기 위해 버퍼 기능 추가하기

기존의 클래스에 버퍼 기능을 추가한다.
BufferedInputStream = DataInputStream + 버퍼기능
BufferedOutputStream = DataOutputStream + 버퍼기능
buf 기능을 사용함으로서 정보를 불러올 때 seek time을 줄여줄 수 있다.
버퍼는 일종의 중간 저장소로서 동작하며, 다음과 같은 방식으로 사용된다.
(단, 오히려 버퍼를 너무 크게설정하면 시간이 더 소요될 수 있다.)
buf는 디스크에서 섹터를 탐색하는 시간적 비용 대신에
RAM을 사용하여 임시 저장소에 덩어리로 가져와서 탐색하기 때문에
디스크에서 탐색 할 경우보다 seek time이 감소한다.
#1. 파일 데이터의 일부를 디스크에서 읽어와 버퍼에 저장한다.
이때 한 번의 디스크 액세스로 여러 바이트를 읽어올 수 있다.
#2. 프로그램은 버퍼에서 데이터를 읽어온다.
버퍼는 주 메모리에 위치하기 때문에 디스크에 비해 훨씬 빠른 액세스 속도를 제공한다.
#3. 버퍼에 있는 데이터를 모두 사용한 경우, 다시 디스크에서 데이터를 읽어와 버퍼를 채운다.
이때 한 번의 디스크 액세스로 여러 바이트를 읽어올 수 있다.
#4. 여러 번의 작은 디스크 액세스보다는 한 번의 큰 디스크 액세스가 이루어지므로
디스크 탐색 시간이 크게 감소한다.
#5. 또한, 버퍼를 통해 데이터를 일시적으로 저장하고 처리할 수 있기 때문에,
프로그램의 전반적인 성능이 향상된다.
* BufferedInputStream = DataInputStream + 버퍼기능
package bitcamp.io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class BufferedDataInputStream extends FileInputStream {
byte[] buf = new byte[8192];
int size; // 배열에 저장되어 있는 바이트의 수
int cursor; // 바이트 읽은 배열의 위치
public BufferedDataInputStream(String name) throws FileNotFoundException {
super(name);
}
@Override
public int read() throws IOException {
if (size == -1) { // 파일의 끝에 도달했다는 의미.
return -1;
}
if (cursor == size) { // 바이트 배열에 저장되어 있는 데이터를 모두 읽었다면,
if ((size = super.read(buf)) == -1) { // 다시 파일에서 바이트 배열로 데이터를 왕창 읽어 온다.
return -1;
}
cursor = 0;
}
return buf[cursor++] & 0x000000ff;
}
@Override
public int read(byte[] arr) throws IOException {
for (int i = 0; i < arr.length; i++) {
int b = this.read();
if (b == -1) {
return i;
}
arr[i] = (byte) b;
}
return arr.length;
}
}
* BufferedOutputStream = DataOutputStream + 버퍼기능
package bitcamp.io;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class BufferedDataOutputStream extends FileOutputStream {
byte[] buf = new byte[8192];
int cursor;
public BufferedDataOutputStream(String name) throws FileNotFoundException {
super(name);
}
@Override
public void write(int b) throws IOException {
if (cursor == buf.length) { // 버퍼가 다차면
super.write(buf); // 버퍼에 들어있는 데이터를 한 번에 출력한다.
cursor = 0; // 다시 커서를 초기화시킨다.
}
buf[cursor++] = (byte) b; // 버퍼에 빈공간이 있다면 버퍼에 저장한다.
}
@Override
public void flush() throws IOException {
super.write(buf, 0, cursor);
cursor = 0;
}
@Override
public void close() throws IOException {
this.flush();
super.close();
}
@Override
public void write(byte[] arr) throws IOException {
for (int i = 0; i < arr.length; i++) {
this.write(arr[i]);
}
}
}* 30. 기능을 확장할 때 상속 대신 Decorator 패턴 적용
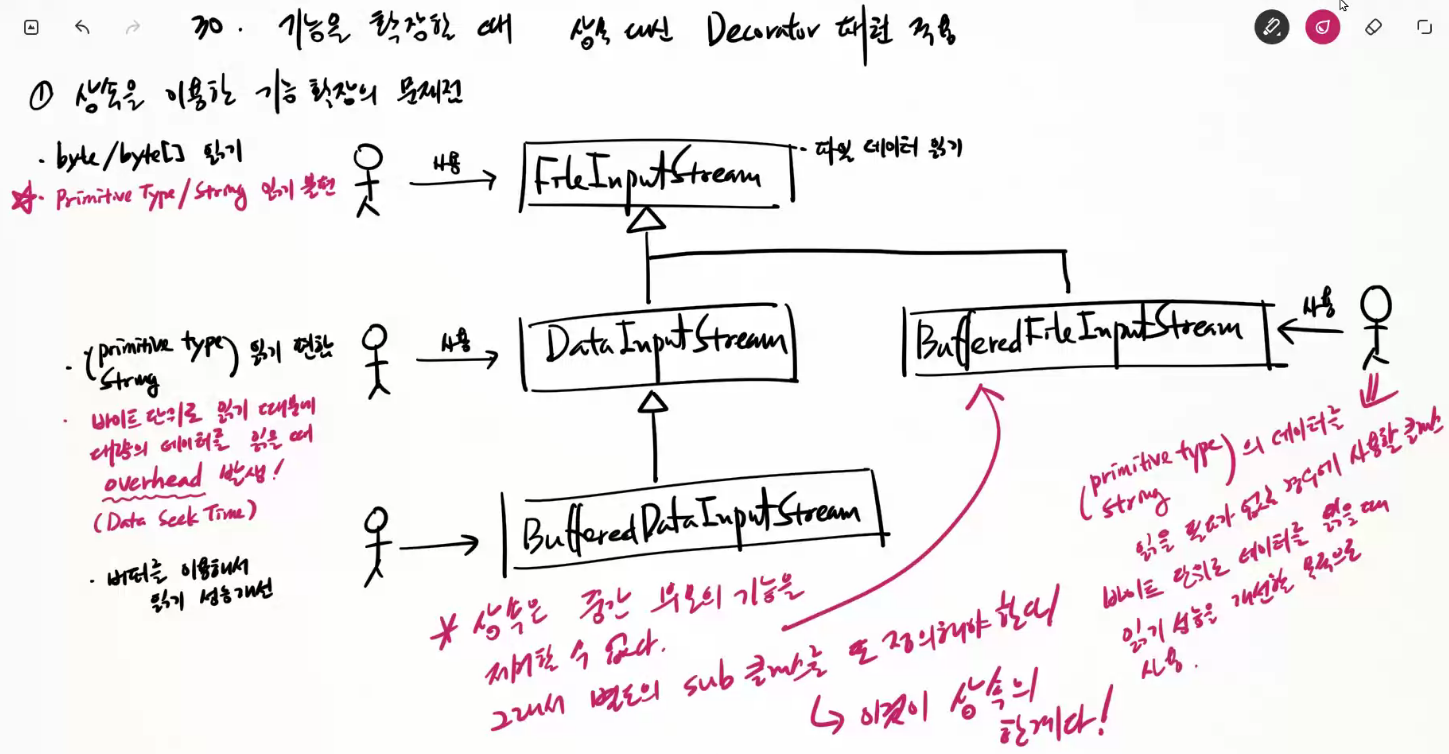
① 상속을 이용한 기능확장의 문제점
상속은 중간 부모의 기능을 제거할 수 없다.
그래서 별도의 sub 클래스를 또 정의해야한다.
이것의 상속의 한계이다.

② 장식품(Decorator) 처럼 기능을 덧붙이고 떼기 쉽게 할 수 있는 설계 구조
Decorator 패턴 (GOF) Compostie 패턴과 유사하다.
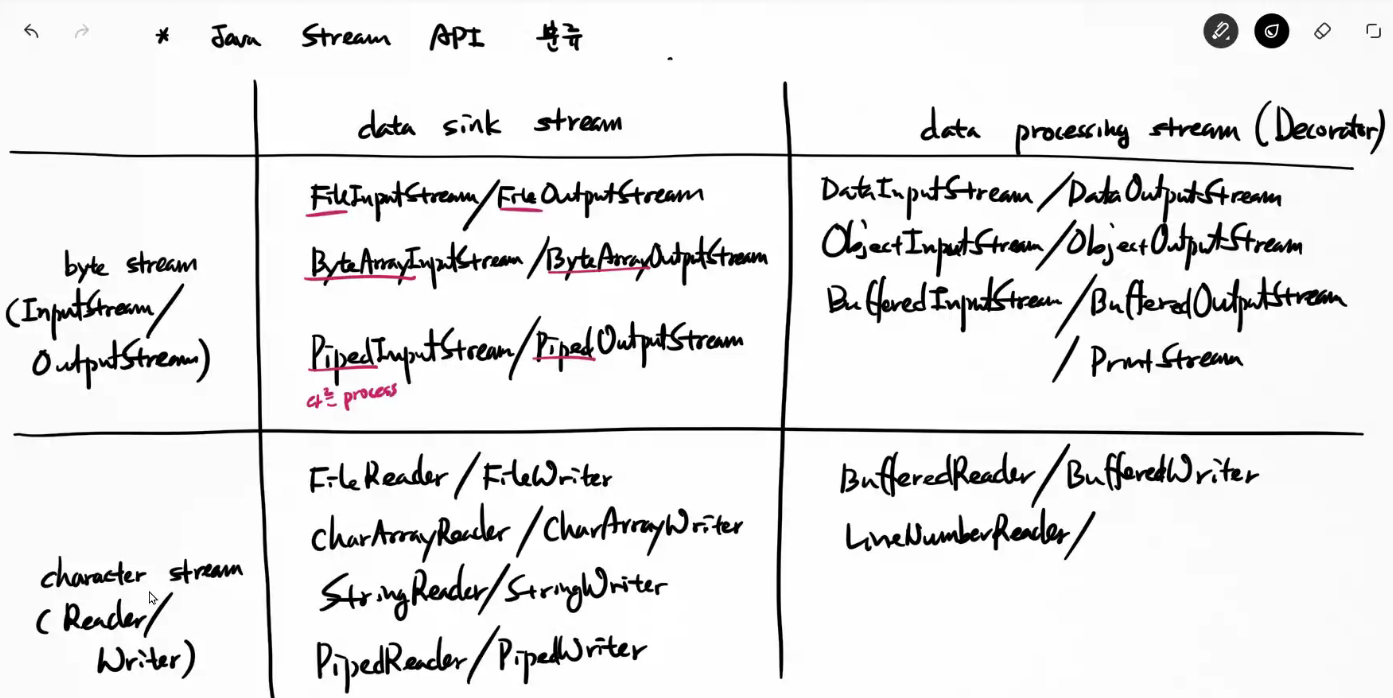
* Java Stream API 분류
https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/io/FileInputStream.html
FileInputStream (Java SE 17 & JDK 17)
All Implemented Interfaces: Closeable, AutoCloseable A FileInputStream obtains input bytes from a file in a file system. What files are available depends on the host environment. FileInputStream is meant for reading streams of raw bytes such as image data.
docs.oracle.com
* 30. 요약 및 직접만든 io 패키지 클래스를 java 패키지로 바꿔주기 (GOF)
기존에 직접만든 io 패키지 클래스를 java 패키지로 적용해주면된다.
import java.io.DataOutputStream;
import java.io.FileInputStream;
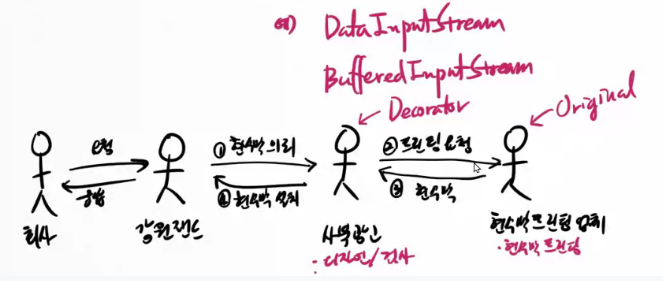
데코레이터 패턴을 적용하는 이유 중 하나는 분업을 통해 읽기 시간을 줄이는 것 !
FileInputStream은 바이트 단위로 데이터를 읽어오는 역할을 해주고.
BufferedStream 을 통해서 디스크에서 데이터를 가져와 데이터 임시 저장소 buf에 저장.
BufferedInputStream은 이 과정에서 데이터를 버퍼에 임시로 저장하여 성능을 향상시킨다.
(디스크에서 섹터를 통해 찾는 것보다 seek time이 절약되기 때문이다.)
DataInputStream은 버퍼를 통해 데이터를 읽어오고 다양한 타입으로 변환하여 읽을 수 있는 기능을 한다.
이것이 데코레이터 패턴이다.
try {
FileInputStream in0 = new FileInputStream("member.data");
BufferedInputStream in1 = new BufferedInputStream(in0); // <= Decorator(장식품) 역할 수행!
DataInputStream in = new DataInputStream(in1);
System.out.println("member.data 파일 정보 읽기 성공 !");
int size = in.readShort(); // 8비트 이동 후 number에 저장