
반응형

오늘은 팀원들과 함께 미니 프로젝트를 진행하는 시간을 가졌다.
프로젝트 주제는 "제주도 퇴근버스 탑승인원 예측"이었다.
우리는 해당 주제에 대해 x 데이터로는 7시부터 12시까지의 승하차 인원을,
y 데이터로는 18시부터 20시까지의 승차인원을 예측하는 작업을 진행했다.
프로젝트에서 나는 주로 머신러닝 모델과 피처 엔지니어링, 그리고 파라미터 값 수정을 담당했다.
우리는 수업 시간에 배웠던 다양한 기법과 도구들을 활용하여 프로젝트를 진행했으며,
train_test_split, KFold, 파라미터 조정, 스케일링(Scaler), 그리고 Optuna와 같은 기능들을 사용하여
모델의 성능을 높이는 데에 집중했다.
catboost, xgboost, LGBM 등 다양한 머신러닝 모델을 실험하면서 r2 값을 향상시키는 중이다.
프로젝트 발표가 끝나면 상세한 리뷰를 통해 우리의 작업 내용을 세밀하게 개선해나갈 계획이다.
발표 이후에는 자세한 내용을 공유하여 다른 팀원들과 함께 발전시키도록 해야겠다.
EarlyStopping_california
[설명]
EarlyStopping은 머신러닝 모델의 학습을 조기에 중단하는 기법 중 하나입니다. 이는 모델이 더 이상 성능 향상이 기대되지 않을 때 학습을 중지하여 시간과 리소스를 절약할 수 있습니다. EarlyStopping을 활용하면 모델이 과적합(overfitting)되는 것을 방지하고 일반화 성능을 향상시킬 수 있습니다.
[코드]
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
import time
from xgboost import XGBRegressor
# Load the California housing dataset
datasets = fetch_california_housing()
x = datasets.data
y = datasets.target
# Split the data into training and testing sets
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.6, test_size=0.2, random_state=100, shuffle=True
)
# Create an XGBoost regression model
model = XGBRegressor(random_state=123, n_estimators=1000, learning_rate=0.1, max_depth=6, gamma=1)
# Fit the model to the training data
model.fit(x_train, y_train,
early_stopping_rounds=20,
eval_set=[(x_train, y_train), (x_test, y_test)],
eval_metric='rmse')
# eval_metirc 회귀모델 : rmse, mae, rmlse..
# eval_metirc 이진모델 : error, auc, logloss..
# eval_metirc 다중모델 : merror, mlogloss..
# Evaluate the model on the testing data
y_predict = model.predict(x_test)
# Calculate the R-squared score
r2 = r2_score(y_test, y_predict)
print('r2 score:', r2)
# r2 score: 0.8315057004630455
[출력]
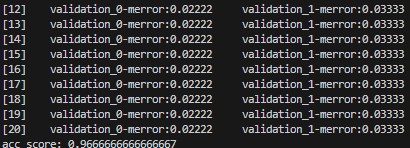
Optuna_california
[설명]
Optuna는 파라미터 튜닝을 자동화하기 위한 오픈소스 파이썬 라이브러리입니다. Optuna는 범용적으로 사용되는 파라미터 튜닝 알고리즘을 제공하여 하이퍼파라미터 공간을 탐색하고 최적의 하이퍼파라미터 조합을 찾을 수 있습니다..
[코드]
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.datasets import fetch_california_housing
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
tf.random.set_seed(77) # weight 난수값 조정
#1. 데이터
datasets = fetch_california_housing()
x = datasets['data']
y = datasets.target
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.8, shuffle=True, random_state=42
)
# kfold
n_splits = 5
random_state = 42
kfold = KFold(n_splits=n_splits, shuffle=True,
random_state=random_state) # KFold : 회귀모델 / StratifiedKFold : 분류모델
# Scaler 적용
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
import optuna
from optuna import Trial, visualization
from optuna.samplers import TPESampler
from sklearn.metrics import mean_absolute_error
from catboost import CatBoostRegressor
import matplotlib.pyplot as plt
def objectiveCAT(trial: Trial, x_train, y_train, x_test):
param = {
'n_estimators' : trial.suggest_int('n_estimators', 500, 4000),
'depth' : trial.suggest_int('depth', 8, 16),
'fold_permutation_block' : trial.suggest_int('fold_permutation_block', 1, 256),
'learning_rate' : trial.suggest_float('learning_rate', 0, 1),
'od_pval' : trial.suggest_float('od_pval', 0, 1),
'l2_leaf_reg' : trial.suggest_float('l2_leaf_reg', 0, 4),
'random_state' :trial.suggest_int('random_state', 1, 2000)
}
# 학습 모델 생성
model = CatBoostRegressor(**param)
CAT_model = model.fit(x_train, y_train, verbose=True) # 학습 진행
# 모델 성능 확인
score = r2_score(CAT_model.predict(x_test), y_test)
return score
# MAE가 최소가 되는 방향으로 학습을 진행
# TPESampler : Sampler using TPE (Tree-structured Parzen Estimator) algorithm.
study = optuna.create_study(direction='maximize', sampler=TPESampler())
# n_trials 지정해주지 않으면, 무한 반복
study.optimize(lambda trial : objectiveCAT(trial, x, y, x_test), n_trials = 5)
print('Best trial : score {}, /nparams {}'.format(study.best_trial.value,
study.best_trial.params))
# 하이퍼파라미터별 중요도를 확인할 수 있는 그래프
print(optuna.visualization.plot_param_importances(study))
# 하이퍼파라미터 최적화 과정을 확인
optuna.visualization.plot_optimization_history(study)
plt.show()
[출력]

QuantileTransformer
[설명]
Quantile은 데이터를 일정한 백분위로 분할하는 기법이며, 데이터의 분포를 이해하고 변환하는 데 사용됩니다. 특히 Quantile은 이상치에 덜 민감하며, 데이터의 비선형 분포를 선형 분포로 변환하는 데 유용합니다.
[코드]
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler, MaxAbsScaler, RobustScaler
from sklearn.preprocessing import QuantileTransformer, PowerTransformer
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
import warnings
warnings.filterwarnings('ignore')
import time
#1. 데이터
datasets = load_iris()
x, y = datasets.data, datasets.target
print(x.shape, y.shape) # (150, 4) (150,)
x_train, x_test, y_train, y_test = train_test_split(
x, y, shuffle=True, random_state=72, train_size=0.8
)
# 스케일링
sts = StandardScaler()
mms = MinMaxScaler()
mas = MaxAbsScaler()
rbs = RobustScaler()
qtf = QuantileTransformer() # QuantileTransformer 는 지정된 분위수에 맞게 데이터를 변환함.
# 기본 분위수는 1,000개이며, n_quantiles 매개변수에서 변경할 수 있음
ptf1 = PowerTransformer(method='yeo-johnson') # 'yeo-johnson', 양수 및 음수 값으로 작동
ptf2 = PowerTransformer(method='box-cox') # 'box-cox', 양수 값에서만 작동
scalers = [sts, mms, mas, rbs, qtf, ptf1, ptf2]
for scaler in scalers:
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
model = RandomForestClassifier()
model.fit(x_train, y_train)
y_predict = model.predict(x_test)
result = accuracy_score(y_test, y_predict)
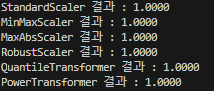
scale_name = scaler.__class__.__name__
print('{0} 결과 : {1:.4f}'.format(scale_name, result), )
#=================================== 결과 =====================================#
# StandardScaler 결과 : 1.0000
# MinMaxScaler 결과 : 1.0000
# MaxAbsScaler 결과 : 1.0000
# RobustScaler 결과 : 1.0000
# QuantileTransformer 결과 : 1.0000
# PowerTransformer 결과 : 1.0000
# ValueError: The Box-Cox transformation can only be applied to strictly positive data
#==============================================================================#
[출력]
SelectFromModel - 최적의 컬럼 조합찾기. 컬럼명까지 출력하기
[설명]
SelectFromModel은 특성 선택(feature selection)을 위한 기법 중 하나입니다. 이는 머신러닝 모델의 학습을 통해 중요한 특성을 선택하는 방법입니다. SelectFromModel은 주어진 모델에서 중요도가 높은 특성들을 선택하여 최종적으로 사용할 특성들을 결정합니다.
[코드]
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, accuracy_score
from sklearn.datasets import load_wine
import time
from xgboost import XGBRegressor,XGBClassifier
# Load the California housing dataset
datasets = load_wine()
x = datasets.data
y = datasets.target
feature_name = datasets.feature_names
print(feature_name)
# Split the data into training and testing sets
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.6, test_size=0.2, random_state=100, shuffle=True
)
# Create an XGBoost regression model
model = XGBClassifier(random_state=123, n_estimators=1000, learning_rate=0.1, max_depth=6, gamma=1)
# Fit the model to the training data
model.fit(x_train, y_train,
early_stopping_rounds=20,
eval_set=[(x_train, y_train), (x_test, y_test)],
eval_metric='merror')
# eval_metirc 회귀모델 : rmse, mae, rmlse..
# eval_metirc 이진모델 : error, auc, logloss..
# eval_metirc 다중모델 : merror, mlogloss..
# Evaluate the model on the testing data
y_predict = model.predict(x_test)
# Calculate the R-squared score
acc = accuracy_score(y_test, y_predict)
print('acc score:', acc)
# r2 score: 0.8315057004630455
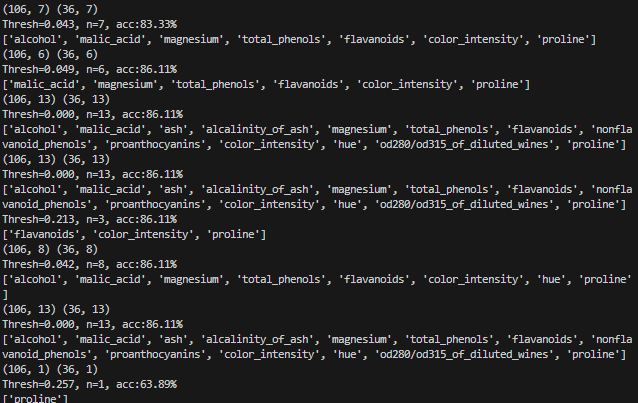
from sklearn.feature_selection import SelectFromModel
thresholds = model.feature_importances_
for thresh in thresholds :
selection = SelectFromModel(model, threshold=thresh, prefit=True)
select_x_train = selection.transform(x_train)
select_x_test = selection.transform(x_test)
print(select_x_train.shape, select_x_test.shape)
selecttion_model = XGBClassifier()
selecttion_model.fit(select_x_train, y_train)
y_predict = selecttion_model.predict(select_x_test)
score = accuracy_score(y_test, y_predict)
print("Thresh=%.3f, n=%d, acc:%.2f%%"%(thresh, select_x_train.shape[1], score*100))
#컬럼명 출력
selected_feature_indices = selection.get_support(indices=True)
selected_feature_names = [feature_name[i] for i in selected_feature_indices]
print(selected_feature_names)
[출력]
반응형