

https://dev-with-gpt.tistory.com/44
[네이버클라우드캠프] 10일차. 인공지능 기초 개념정리 및 기초코드 실습 (딥러닝,퍼셉트론,옵티
0. 딥러닝에서의 매개변수 탐색과 최적화 딥러닝은 함수의 최적의 매개변수를 찾는 것을 목표로 한다. 일반적으로 y = wx + b와 같은 수학적인 함수로 모델을 표현한다. 이때, 딥러닝은 최적의 매
dev-with-gpt.tistory.com
9. 회귀분석

회귀분석(Regression)은 주로 연속된 값을 예측하는 문제에 사용되며, 과거 데이터를 기반으로 미래 값을 예측하는 데 활용된다. 예를 들어, 주가 데이터를 이용하여 과거의 주가 패턴을 분석하고, 이를 기반으로 미래의 주가를 예측하는 것은 회귀분석의 예시이다. 이를 통해 투자자나 거래자들은 주가의 상승 또는 하락을 예측하여 이를 활용할 수 있다.
또한, 자동차의 배기량, 연식, 주행거리 등과 같은 중고차 정보를 이용하여 해당 차량의 가격을 예측하는 것도 회귀분석의 예시이다. 이를 통해 중고차 시장에서의 가격 형성 요인을 파악하고, 구매자나 판매자가 적정한 가격을 결정하는 데에 도움을 줄 수 있다.
회귀분석은 다양한 분야에서 활용되며, 주어진 입력 변수와 출력 값 사이의 관계를 모델링하여 연속적인 값을 예측하는 데에 사용된다. 데이터의 특성에 따라 적절한 회귀분석 모델과 방법을 선택하여 문제에 적용할 수 있다.
10. 결정계수 R2 score

R-squared(R2)는 선형 회귀 모델의 적합도를 나타내는 측정값으로, 훈련된 모델이 주어진 데이터에 얼마나 적합한지를 확인하는 통계적 방법이다. R2 스코어는 0과 1 사이의 값을 가지며, 1에 가까울수록 선형 회귀 모델이 데이터에 대해 높은 연관성을 가지고 있다고 해석된다.
이는 회귀 모델이 종속 변수의 변동성을 얼마나 설명하는지를 나타내는 지표로, 1에 가까울수록 모델이 데이터를 잘 설명하고 예측하는 것을 의미한다.
따라서, R-squared는 선형 회귀 모델의 적합도를 평가하는 중요한 지표이며, 높은 R2 스코어를 가진 모델은 데이터에 대해 더 높은 설명력을 갖고 있다고 해석할 수 있다.
11. 분류분석
분류분석(Classification)은 주어진 데이터를 기반으로 클래스 또는 종류를 예측하는 문제에 사용되며, 이진 분류와 다중 분류로 나뉘어진다. 이진 분류(Binary Classification)는 두 개의 클래스 중에서 하나를 선택하는 문제이고, 다중 분류(Multi Classification)는 세 개 이상의 클래스 중에서 하나를 선택하는 문제이다.
분류분석은 주어진 입력 변수를 기반으로 각 클래스에 속할 확률을 예측하고, 가장 높은 확률을 가진 클래스를 선택하는 방식으로 동작하여 주어진 데이터에 대해 정확한 클래스 레이블을 예측하는 데에 활용된다.
12. 원 핫 인코딩 (One Hot Encoding)
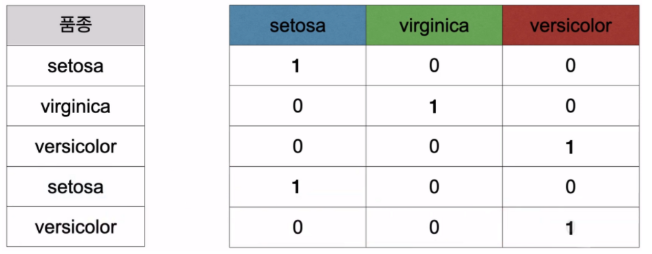
원 핫 인코딩(One Hot Encoding)은 범주형 데이터를 이진 형태의 벡터로 변환하는 방법이다. 각 범주에 대해 고유한 이진 벡터를 생성하고, 해당 범주에 해당하는 원소는 1로, 나머지 원소는 0으로 표현한다. 이를 통해 범주형 데이터를 머신러닝 알고리즘이 처리할 수 있는 형태로 변환할 수 있다.
13. 난수값 (random_state)

난수값(random_state)은 머신러닝 알고리즘 및 데이터 분할 작업에서 사용되는 난수 생성기의 시드 값이다. random_state를 설정하면, 무작위로 생성되는 난수의 패턴이 고정되어 동일한 결과를 얻을 수 있게 되며, 이는 알고리즘의 결과를 재현 가능하게 만든다
https://dev-with-gpt.tistory.com/49
파이썬 딥러닝 회귀분석과 분류분석, 손실함수와 활성화 함수
1. Train_Test_Split [코드] import numpy as np from keras.models import Sequential from keras.layers import Dense from sklearn.model_selection import train_test_split # 1. 데이터 x = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]) y = np
dev-with-gpt.tistory.com
1. Train_Test_Split
[코드]
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
# 1. 데이터
x = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
y = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.3, # Test data size 보통 0.3
train_size=0.7, # Train data size 보통 0.7
random_state=100, # data를 난수값에 의해 추출한다는 의미이며, 중요한 하이퍼 파라미터
shuffle=True # data를 섞어서 가지고 올 것인지 여부
)
# 2. 모델구성
model = Sequential()
model.add(Dense(14,input_dim=1)) #입력층 train data 숫자
model.add(Dense(50)) #은닉층
model.add(Dense(1)) #출력층
# 3. 컴파일 훈련
model.compile(loss='mse',optimizer='adam')
model.fit(x_train, y_train, epochs=100, batch_size=1) # train 데이터 넣기
# 4. 평가 예측
loss = model.evaluate(x_test, y_test) # test 데이터 넣기
print('loss : ', loss)
result = model.predict([21])
print('21의 예측값 : ', result)[출력]

[의미]
Train-Test Split은 머신러닝 모델을 평가하기 위해 데이터를 나누는 과정입니다.
일반적으로 데이터는 훈련 데이터와 테스트 데이터로 나누어집니다. 훈련 데이터는 모델을 학습시키는 데에 사용되고, 테스트 데이터는 학습된 모델을 평가하는 데에 사용됩니다.
Train-Test Split의 목적은 모델이 처음에 본 데이터에 대한 예측 성능을 평가하기 위해 사용됩니다. 훈련 데이터로 모델을 학습시킨 후, 테스트 데이터로 모델의 성능을 평가하여 일반화(generalization) 능력을 확인합니다.
일반적으로 데이터의 일정 비율을 훈련 데이터와 테스트 데이터로 나눕니다. 예를 들어, 70%의 데이터를 훈련 데이터로 사용하고, 나머지 30%의 데이터를 테스트 데이터로 사용하는 것은 일반적인 방법입니다.
데이터를 나누는 과정에서 데이터의 순서를 랜덤하게 섞어서 골고루 분포되도록 합니다.
Train-Test Split은 모델의 성능을 정확하게 평가하기 위해 필수적인 과정이며, 모델의 일반화 능력을 신뢰할 수 있도록 도와줍니다.
2. matplotlib– scatter (산점도)
[코드]
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
# 1. 데이터
x = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
y = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.3, # Test data size 보통 0.3
train_size=0.7, # Train data size 보통 0.7
random_state=100, # data를 난수값에 의해 추출한다는 의미이며, 중요한 하이퍼 파라미터
shuffle=True # data를 섞어서 가지고 올 것인지 여부
)
# 2. 모델구성
model = Sequential()
model.add(Dense(14,input_dim=1)) #입력층 train data 숫자
model.add(Dense(50)) #은닉층
model.add(Dense(1)) #출력층
# 3. 컴파일 훈련
model.compile(loss='mse',optimizer='adam')
model.fit(x_train, y_train, epochs=100, batch_size=1) # train 데이터 넣기
# 4. 평가 예측
loss = model.evaluate(x_test, y_test) # test 데이터 넣기
print('loss : ', loss)
result = model.predict([21])
print('21의 예측값 : ', result)
y_predict = model.predict(x)
#### scatter 시각화
import matplotlib.pyplot as plt
plt.scatter(x, y)
plt.plot(x, y_predict, color='Red')
plt.show()[출력]

[의미]
matplotlib의 scatter 함수는 산점도를 그리기 위해 사용됩니다. 산점도는 두 개의 변수로 이루어진 데이터를 좌표평면 상에 점으로 표현하는 그래프입니다. 산점도는 주로 두 변수 간의 상관 관계를 시각화하기 위해 사용됩니다. 점들의 분포를 통해 변수들 간의 관계를 파악할 수 있습니다.
3. R2 score ( 결정계수)
[코드]
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
# 1. 데이터
x = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
y = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.3, # Test data size 보통 0.3
train_size=0.7, # Train data size 보통 0.7
random_state=100, # data를 난수값에 의해 추출한다는 의미이며, 중요한 하이퍼 파라미터
shuffle=True # data를 섞어서 가지고 올 것인지 여부
)
# 2. 모델구성
model = Sequential()
model.add(Dense(14,input_dim=1)) #입력층 train data 숫자
model.add(Dense(50)) #은닉층
model.add(Dense(1)) #출력층
# 3. 컴파일 훈련
model.compile(loss='mse',optimizer='adam')
model.fit(x_train, y_train, epochs=100, batch_size=1) # train 데이터 넣기
# 4. 평가 예측
loss = model.evaluate(x_test, y_test) # test 데이터 넣기
print('loss : ', loss)
y_predict = model.predict(x)
### R2 score
from sklearn.metrics import r2_score, accuracy_score
r2 = r2_score(y, y_predict)
print('r2스코어 : ', r2)
# result(1)
# loss : 1.5082454174475401e-09
# r2스코어 : 0.9999999999709706[출력]

[의미]
R-squared(R2)는 선형 회귀 모델의 적합도를 나타내는 측정값으로, 훈련된 모델이 주어진 데이터에 얼마나 적합한지를 확인하는 통계적 방법이다. R2 스코어는 0과 1 사이의 값을 가지며, 1에 가까울수록 선형 회귀 모델이 데이터에 대해 높은 연관성을 가지고 있다고 해석된다.
4. Validation Split
실습 Yet
[의미]
Validation Split은 모델을 훈련하기 전에 데이터를 훈련 세트와 검증 세트로 나누는 과정입니다. 일반적으로 데이터를 세 가지로 나누는데, 훈련 세트, 검증 세트, 테스트 세트로 구성됩니다.
주요 단계는 다음과 같습니다:
- 데이터 준비: 먼저, 전체 데이터를 훈련에 사용할 데이터와 모델의 성능을 평가하는 데 사용할 데이터로 나눕니다.
- 데이터 분할: 데이터를 훈련 세트와 검증 세트로 나눕니다. 일반적으로 사이킷런의 train_test_split 함수를 사용합니다. train_test_split 함수는 데이터를 무작위로 섞은 후 지정한 비율에 따라 데이터를 분할합니다.
- 모델 훈련 및 검증: 훈련 세트로 모델을 훈련시키고, 검증 세트를 사용하여 모델의 성능을 평가합니다. 훈련 과정에서 검증 세트의 성능 지표를 확인하며 모델을 조정하고 개선하는 데 사용됩니다.
- 모델 평가: 모델을 훈련한 후에는 테스트 세트를 사용하여 모델의 일반화 성능을 평가합니다. 이 단계는 모델의 최종 성능을 평가하고 새로운 데이터에 대한 예측력을 확인하는 데 사용됩니다.
5. 분류분석-이진분류
[코드]
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, accuracy_score
from sklearn.datasets import load_breast_cancer
import time
#1. 데이터
datasets = load_breast_cancer()
print(datasets.DESCR)
print(datasets.feature_names)
# 30개
# #['mean radius' 'mean texture' 'mean perimeter' 'mean area'
# 'mean smoothness' 'mean compactness' 'mean concavity'
# 'mean concave points' 'mean symmetry' 'mean fractal dimension'
# 'radius error' 'texture error' 'perimeter error' 'area error'
# 'smoothness error' 'compactness error' 'concavity error'
# 'concave points error' 'symmetry error' 'fractal dimension error'
# 'worst radius' 'worst texture' 'worst perimeter' 'worst area'
# 'worst smoothness' 'worst compactness' 'worst concavity'
# 'worst concave points' 'worst symmetry' 'worst fractal dimension']
x = datasets.data
y = datasets.target
print(x.shape, y.shape) #(569, 30) (569,)
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.7, random_state=100, shuffle=True
)
#2. 모델구성
model = Sequential()
model.add(Dense(100, activation='linear', input_dim=30))
model.add(Dense(100, activation='relu'))
model.add(Dense(100, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(1, activation='sigmoid')) # 이진분류는 무조건 아웃풋 활성화
# 활성화 함수를 'sigmoid'로 해줘야한다.
#3. 컴파일, 훈련
model.compile(loss='binary_crossentropy', optimizer='adam',
metrics=['accuracy','mse'])
start_time = time.time()
model.fit(x_train, y_train, epochs=100, batch_size=200)
end_time = time.time() - start_time
#4. 평가,예측
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
# y_predict = np.where(y_predict > 0.5, 1, 0) # where 반올림
y_predict = np.round(y_predict)
acc = accuracy_score(y_test, y_predict)
print('loss:', loss)
print('accuracy:', acc)
print('걸린시간:', end_time)
#결과값
# loss: [0.28832826018333435, 0.9064327478408813, 0.07380938529968262]
# accuracy: 0.9064327485380117
# 1.230656623840332[출력]

[의미]
R-squared(R2)는 선형 회귀 모델의 적합도를 나타내는 측정값으로, 훈련된 모델이 주어진 데이터에 얼마나 적합한지를 확인하는 통계적 방법이다. R2 스코어는 0과 1 사이의 값을 가지며, 1에 가까울수록 선형 회귀 모델이 데이터에 대해 높은 연관성을 가지고 있다고 해석된다.
6. 분류분석-다중분류
[코드]
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, accuracy_score
from sklearn.datasets import load_iris
import time
#1. 데이터
datasets = load_iris()
print(datasets.DESCR)
print(datasets.feature_names)
#['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
x = datasets.data
y = datasets.target
print(x.shape,y.shape) # (150, 4) (150,) #input_dim = 4
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.7, random_state=100, shuffle=True
)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
print(y_test)
#2. 모델 구성
model = Sequential()
model.add(Dense(100,input_dim=4))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(500))
model.add(Dense(3, activation='softmax'))
#3.컴파일, 훈련
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam',
metrics=['accuracy'])
start_time = time.time()
model.fit(x_train, y_train, epochs=100, batch_size=100)
end_time = time.time() - start_time
#4. 평가,예측
# y_predict = model.predict(x_test)
# y_predict = np.round(y_predict)
# loss= model.evaluate(x_test, y_test)
# acc = accuracy_score(y_test, y_predict)
#
y_predict = model.predict(x_test)
y_predict = np.argmax(y_predict, axis=1)
#
print(y_predict)
loss= model.evaluate(x_test, y_test)
acc = accuracy_score(y_test, y_predict)
# np.argmax(,axis=n) 함수는 배열에서 가장 큰 값의
# 인덱스를 반환하는 함수입니다.
# axis=1을 지정하여 각 행에서 가장 큰 값의 인덱스를 추출하면,
# 다중 클래스로 예측된 결과를 얻을 수 있습니다.
# axis = 0 (행), axis = 1 (열)
print('loss : ', loss)
print('acc : ', acc)
print('걸린시간 : ', end_time)[출력]

[의미]
다중 분류(Multi-Class Classification)는 세 개 이상의 클래스 중 하나를 선택하는 문제입니다. 예를 들어, 손글씨 숫자를 0부터 9까지의 클래스로 분류하는 문제가 다중 분류에 해당합니다.
다중 분류를 위한 손실 함수로는 주로 Categorical Cross Entropy(범주형 크로스 엔트로피)를 사용합니다. Categorical Cross Entropy는 다중 클래스 간의 오차를 계산하여 모델을 학습시키는 데 사용됩니다.
활성화 함수로는 Softmax 함수가 주로 사용됩니다. Softmax 함수는 입력값들을 확률 형태로 변환하여 다중 클래스에 대한 확률 분포를 출력합니다. 각 클래스에 대한 확률값의 합은 1이 되도록 정규화됩니다. 예측값은 확률이 가장 높은 클래스로 분류됩니다.
또한, 활성화 함수로는 Sigmoid 함수나 Linear 함수도 사용할 수 있습니다. Sigmoid 함수는 이진 분류에서 확률값을 표현하는 데 사용되었지만, 다중 분류에서는 각 클래스마다 독립적인 이진 분류를 수행하여 확장할 수도 있습니다. Linear 함수는 회귀 분석에서 사용되는 활성화 함수로, 다중 분류 문제에서는 주로 사용되지 않습니다.
따라서 다중 분류 모델은 입력 데이터를 받아들이는 입력층, 은닉층에서 활성화 함수로 ReLU를 사용하는 층, 마지막 출력층에서 활성화 함수로 Softmax를 사용하는 층으로 구성될 수 있습니다. 손실 함수로는 Categorical Cross Entropy를 사용하여 모델을 학습시킬 수 있습니다.
다중 분류 문제에서 주로 사용되는 개념 및 기법
- One-hot encoding:
- 다중 분류에서 클래스를 표현하기 위해 사용되는 기법입니다.
- 각 클래스는 이진 벡터로 표현되며, 해당 클래스에 해당하는 인덱스에는 1이 표시되고 나머지 인덱스에는 0이 표시됩니다.
- 예를 들어, 클래스 A, B, C가 있을 때, A는 [1, 0, 0], B는 [0, 1, 0], C는 [0, 0, 1]과 같이 표현됩니다.
- 주로 모델의 출력층에서 다중 클래스를 예측하기 위해 사용됩니다.
- Sparse categorical cross entropy:
- 다중 분류에서 손실 함수로 사용되는 하나의 종류입니다.
- 정수 형태로 표현된 실제 클래스 값을 인코딩하지 않고, 정수 형태로 그대로 사용하여 손실을 계산합니다.
- 이는 클래스를 one-hot 형식으로 인코딩하지 않고, 정수로 표현된 클래스 값을 사용할 때 유용합니다.
- np.argmax:
- NumPy의 함수로, 다차원 배열에서 가장 큰 값의 인덱스를 반환하는 역할을 합니다.
- 다중 분류에서 모델의 출력 결과인 확률 벡터에서 가장 큰 값의 인덱스를 선택하는데 사용됩니다.
- 주로 모델의 예측 결과를 정수 형태로 얻을 때 사용됩니다.
이러한 개념과 기법들은 다중 분류 문제에서 클래스를 표현하고 손실을 계산하며, 예측 결과를 얻는 데에 활용됩니다.
활성화함수
활성화 함수 (Activation Function)인 linear, relu, sigmoid, softmax은 신경망 모델에서 주로 사용되는 함수입니다. 각 함수의 특징과 사용되는 경우에 대해 설명하겠습니다:
- Linear (선형 함수):
- 가장 기본적인 활성화 함수로, 입력과 동일한 값을 출력합니다.
- 주로 회귀(Regression) 문제에서 출력층의 활성화 함수로 사용됩니다.
- 입력과 출력 사이의 선형 관계를 표현하기 위해 사용됩니다.
- ReLU (Rectified Linear Unit):
- 입력이 0보다 작을 경우 0을 출력하고, 0보다 큰 경우 입력 값을 그대로 출력합니다.
- 비선형 함수로, 신경망의 은닉층에서 주로 사용됩니다.
- 입력에 대해 더 강한 비선형성을 제공하며, 그레이디언트 소실 문제를 완화할 수 있습니다.
- Sigmoid (로지스틱 시그모이드):
- 입력을 0과 1 사이의 값으로 압축하여 출력합니다.
- 이진 분류(Binary Classification) 문제에서 출력층의 활성화 함수로 사용됩니다.
- 출력 값이 확률로 해석될 수 있어, 입력이 클래스에 속할 확률을 표현하는 데 사용됩니다.
- 그러나 그레디언트 소실 문제와 출력 값의 제한된 범위가 있을 수 있는 단점이 있습니다.
- Softmax:
- 다중 클래스 분류(Multi-Class Classification) 문제에서 출력층의 활성화 함수로 사용됩니다.
- 입력값들을 정규화하여 클래스에 대한 확률 분포를 생성합니다.
- 출력 값들의 합이 1이 되며, 각 클래스에 속할 확률로 해석됩니다.
- 다중 클래스를 예측하고자 할 때 사용되며, Cross Entropy와 함께 사용됩니다.
각 활성화 함수는 모델의 특성과 문제에 따라 적절하게 선택되며, 모델의 학습과 성능에 영향을 미칩니다. 적절한 활성화 함수를 선택하여 모델을 구성하고, 학습 및 예측에 활용해야 합니다.